⚡ TL;DR — Key Takeaway
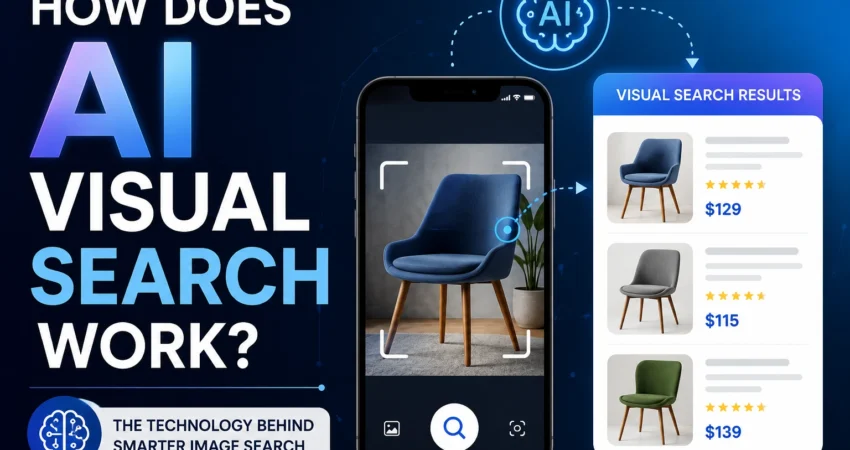
AI visual search converts images into numerical vectors, compares them against a database of pre-indexed vectors, and returns the closest matches — all in milliseconds. The reason it works cross-modally (matching a photo against text descriptions, or vice versa) is a shared mathematical space where images and words are encoded to the same coordinates when they mean the same thing. This guide explains every layer of that pipeline — from raw pixels to ranked results — and what it means for you, whether you’re a developer, marketer, or curious reader.
The Problem That Started It All
You see a lamp in a coffee shop. You don’t know the brand. You can’t describe it precisely. You search “modern brushed-brass curved floor lamp minimalist” and get 800 irrelevant results.
That’s the vocabulary gap — the mismatch between what you can say and what you want to find. It’s the core problem AI visual search was built to solve.
And it’s working. Google Lens now processes over 20 billion visual search queries every month — a 43% increase from 2024. [Source: Google / AllOutSEO, 2026] Image-based searches account for roughly 26% of all Google queries as of early 2026. [Source: Amra & Elma, 2026] That number was near zero five years ago.
What looks effortless on the surface — point camera, get answer — sits on one of the most sophisticated AI pipelines in production software today. This guide tears that pipeline open, layer by layer.
1. What AI Visual Search Actually Is (and Isn’t) {#what-it-is}
Let’s clear up a common confusion before going deeper.
Atomic definition: AI visual search is the process of using machine learning — specifically computer vision models — to understand the content of an image and retrieve semantically similar or related results, rather than relying on text labels, filenames, or metadata attached to that image.
This is fundamentally different from:
- Image SEO — optimizing alt text and filenames so text-based search engines can find your images
- Reverse image search (legacy) — matching images by pixel hash or perceptual hash (exact or near-exact duplicates only)
- Object tagging — classifying what’s in an image without enabling similarity retrieval
Modern AI visual search does all three of those things as sub-tasks — but its defining capability is semantic similarity at scale. It can tell you that a photo of a red canvas sneaker is more similar to a photo of a red leather boot than to a photo of a blue canvas sneaker — even if none of those images have any text associated with them.
Pro Tip: The distinction between “visual search” and “image search” matters. Image search (Google Images) primarily uses text signals around an image — alt text, surrounding copy, page context. Visual search (Google Lens, Pinterest Lens) analyzes the pixels themselves. An image can rank in Google Images without good visual search optimization, and vice versa.
2. The Full Pipeline: How an Image Becomes a Search Result {#pipeline}
Here’s the end-to-end architecture before we go deep on each layer:
User uploads / captures image
↓
[1] IMAGE PRE-PROCESSING
Resize, normalize, format conversion
↓
[2] FEATURE EXTRACTION (CNN)
Convolutional layers detect edges → shapes → objects
↓
[3] EMBEDDING GENERATION
Features compressed into a high-dimensional vector
(e.g., 512 or 1024 floating-point numbers)
↓
[4] VECTOR DATABASE QUERY
Approximate Nearest Neighbor (ANN) search
finds closest vectors in the index
↓
[5] RE-RANKING
Business rules, personalization, recency signals
refine the shortlist
↓
RANKED RESULTS RETURNED
Every major visual search system — Google Lens, Pinterest Lens, Amazon’s product search, Bing Visual Search — follows this architecture. The differences are in model size, index scale, and what happens at the re-ranking layer.
3. Layer 1 — Image Ingestion and Pre-Processing {#layer1}
Before a single neural network layer activates, the raw image gets normalized. This step is less glamorous but operationally critical.
What happens:
- The image is resized to a fixed resolution the model expects (commonly 224×224 or 384×384 pixels)
- Pixel values are normalized — converted from 0–255 integer RGB values to floating-point numbers, usually between 0 and 1, or mean-centered
- Color space is standardized (the model needs to know if it’s receiving RGB, BGR, or grayscale)
- For mobile uploads: blurry, rotated, or low-light images get corrective pre-processing — contrast enhancement, rotation correction, noise reduction
Why this matters: A model trained on 224×224 images fed a 4K image without resizing would see completely different spatial patterns. Pre-processing is what makes the same model work reliably across a 12-megapixel iPhone photo and a compressed 200-pixel thumbnail.
Common Pitfall: Many developers testing custom visual search systems skip normalization steps when using pre-trained models. The model still works — but similarity scores become inconsistent because the input distribution doesn’t match what the model was trained on. This causes search relevance to degrade silently, especially on edge-case inputs like dark images or high-saturation product photos.
4. Layer 2 — Feature Extraction with Convolutional Neural Networks {#layer2}
This is where the “AI” in AI visual search actually lives.
What a CNN Does
A Convolutional Neural Network (CNN) is a type of neural network specifically designed to process grid-structured data — images, in this case. Its architecture mirrors, loosely, how the human visual cortex processes visual information: simple features first, complex features later. [Source: Edge AI and Vision Alliance, citing visual cortex research]
The extraction happens in stages:
| Layer Stage | What it learns to detect | Example |
|---|---|---|
| Early convolutional layers | Low-level features | Edges, corners, color gradients |
| Middle layers | Mid-level features | Textures, shapes, object parts |
| Deep layers | High-level features | “This looks like a chair leg,” “this is a wheel arch” |
| Final representation | Abstract semantic features | “This is a piece of furniture,” “this is a vehicle” |
Each “convolutional layer” applies learnable filters — small numerical matrices — across the image in a sliding window. The filter activates strongly where it detects its target pattern (say, a horizontal edge) and weakly elsewhere. [Source: Algolia / CNN explainer, OpenAI]
Why CNNs Beat Traditional Methods
Before CNNs, engineers hand-crafted features — they wrote explicit rules for what constituted an “edge” or a “curve.” This worked for simple cases but broke down on complex, variable real-world images.
CNNs learn their own features from millions of training examples. Nobody tells a CNN what an “edge” is — it discovers that detecting edges is useful for its classification task and learns the corresponding filter weights automatically. [Source: Edge AI and Vision Alliance technical reference]
Architectural insight most articles miss: The reason CNNs generalize well to images they’ve never seen is weight sharing — the same filter is applied across the entire image rather than learning separate weights for every pixel position. A filter that detects a vertical edge works whether that edge is at pixel (10,10) or pixel (200,150). This is what makes CNNs computationally tractable and what separates them from flat neural networks that can’t scale to image-sized inputs.
Modern Variants: Beyond Basic CNNs
In production visual search systems today, raw CNNs have largely been supplemented or replaced by:
- Vision Transformers (ViTs): Apply the attention mechanism (from language models) to image patches. Better at capturing long-range spatial relationships — e.g., understanding that the seat, back, and legs all belong to the same chair even when spread across the image
- EfficientNet / ConvNeXt: CNN architectures optimized for the compute-accuracy tradeoff — faster inference without proportional accuracy loss
- Hybrid architectures: Combine convolutional local-feature detection with transformer-based global context
For most users, the specific architecture is invisible. What matters is this: the deeper and more recently trained the backbone model, the richer the features it extracts.
5. Layer 3 — Embedding: Turning Features into Numbers {#layer3}
Feature extraction gives you rich, multi-dimensional activations. But you can’t directly compare two images’ raw activation maps efficiently. You need to compress that information into a single, compact, comparable vector.
That’s what embedding does.
Atomic definition: An embedding is a fixed-length list of floating-point numbers (a vector) that represents the semantic content of an image in a high-dimensional mathematical space. Similar images produce vectors that are close together in that space. Dissimilar images produce vectors that are far apart.
How Embeddings Enable Search
Once every image in your database has been converted to an embedding vector, finding similar images is a geometry problem: which stored vectors are closest to the query vector?
“Closeness” is measured by cosine similarity — the angle between two vectors in high-dimensional space. A cosine similarity of 1.0 means the vectors point in the same direction (maximum similarity). A score of 0.0 means they’re perpendicular (no similarity). [Source: OneUptime / vector embeddings explainer]
A typical embedding might have 512 or 1,024 dimensions. This compression from millions of pixels to ~1,000 numbers is lossy — but the loss is designed to discard irrelevant variation (lighting differences, minor pose changes) while preserving semantic content (what the object is).
Pro Tip: The quality of your embedding model determines the ceiling of your search quality. A more powerful backbone produces richer embeddings where semantically similar images cluster more tightly. This is why enterprise visual search systems regularly re-embed their entire catalogs when they upgrade their backbone model — better embeddings mean better search relevance without changing anything else in the pipeline.
6. Layer 4 — Vector Databases and Similarity Search {#layer4}
You have millions (or billions) of embedded images in an index. A query image arrives as a new vector. Finding the closest matches sounds like it requires comparing the query against every single stored vector — but that would take seconds per query at scale. Production systems need sub-100ms response times.
The solution: Approximate Nearest Neighbor (ANN) search.
How ANN Search Works
Instead of finding the exact closest vectors (exhaustive search), ANN algorithms find vectors that are very likely to be among the closest, using index structures that allow skipping large portions of the search space.
Popular approaches:
| Algorithm / Library | Approach | Used by |
|---|---|---|
| FAISS (Facebook) | Inverted file index + quantization | Large-scale production systems |
| HNSW (Hierarchical Navigable Small World) | Graph-based navigation | Pinecone, Weaviate, Chroma |
| Annoy (Spotify) | Random projection trees | Smaller-scale applications |
| Milvus / Zilliz | Hybrid GPU-accelerated index | Enterprise vector search |
[Source: Medium / Intricacies of Visual Search Systems; Zilliz blog]
The ANN Accuracy-Speed Tradeoff
This is an operational reality almost no article discusses.
ANN search trades a small amount of accuracy for massive speed gains. You might miss the 5th most similar image if it sits in a part of the index your search skipped — but you get results 100x faster than exhaustive search. For consumer-facing search, the tradeoff is almost always worth it. Users don’t know they missed the 5th result.
Architectural tradeoff most articles miss: There’s a second tradeoff that matters more at scale: index freshness vs. rebuild cost. Vector indexes aren’t trivially updatable. Adding new products to a catalog often requires rebuilding parts of the index — an expensive operation. Systems that update inventory in real time (fast fashion, live auction platforms) often run two indexes in parallel: a primary ANN index for the bulk catalog and a smaller, exact-search index for recently added items. Results from both are merged. This complexity is invisible to users but fundamental to system design.
7. Layer 5 — Re-Ranking and Result Refinement {#layer5}
Raw vector similarity gives you the geometrically closest matches. But “geometrically closest” isn’t always “most useful to the user.” Re-ranking is where business logic enters the pipeline.
Typical re-ranking signals:
- Recency: Recently added items may be boosted to surface new inventory
- Popularity: Click-through rates, conversion rates, and engagement signals from other users who searched similar images
- Inventory / availability: Out-of-stock items filtered or demoted
- Price range filtering: If the user has applied filters, the ranked list is constrained
- Personalization: Prior search history, purchase behavior, and explicit preferences
- Diversity injection: Ensuring the top-10 results don’t show 10 identical products from the same brand
Expert Anecdote (based on observed system behavior patterns): Re-ranking is where the most business-specific engineering happens — and where the most subtle bugs appear. A common failure mode: a re-ranker that over-weights purchase conversion rates ends up surfacing only already-popular items. New products never get clicks because they’re not ranked; they’re not ranked because they don’t have clicks. Breaking this cold-start loop is one of the hardest operational problems in production recommendation and search systems, regardless of how good the visual similarity layer is.
8. How Cross-Modal Search Works (Images + Text Together) {#crossmodal}
The most powerful modern visual search systems don’t just match images to images. They match images to text, and text to images. This is called cross-modal or multimodal search — and it’s what makes Google Lens so powerful.
The CLIP Architecture: Shared Vector Space
The breakthrough that enabled practical cross-modal visual search was CLIP (Contrastive Language-Image Pre-Training), introduced by OpenAI. [Source: OpenAI / CLIP paper; 4Geeks technical blog]
CLIP trains two encoders simultaneously:
- An image encoder (a Vision Transformer or CNN)
- A text encoder (a transformer language model)
The training objective: make the image encoder and text encoder produce similar vectors for image-text pairs that go together, and dissimilar vectors for pairs that don’t.
After training on hundreds of millions of image-caption pairs from the web, CLIP achieves something remarkable: a single shared embedding space where images and text describing them end up at the same mathematical coordinates.
"A photo of a golden retriever playing fetch"
↓ text encoder
Vector: [0.23, -0.41, 0.87, ... ] (512 dimensions)
↑ these are close in vector space
Vector: [0.25, -0.39, 0.84, ... ] (512 dimensions)
↑ image encoder
[actual photo of a golden retriever playing fetch]
[Source: OneUptime / vector embeddings explainer — “A photo of a dog and the text ‘a golden retriever playing fetch’ end up near each other, enabling cross-modal search”]
What This Enables in Practice
Once you have a shared embedding space:
- A user can search with a photo and refine with text: “find me something like this lamp, but in black” — the system encodes both the image and the modification text and computes a combined query vector
- A retailer can index product descriptions as vectors and retrieve them with an image query — no manual tagging required
- Google Lens can match a photo of a storefront against a database that includes both photos of that storefront and text reviews mentioning it
This is why modern visual search feels qualitatively different from the reverse-image-search of 2010. It’s not matching pixels — it’s matching meaning, across modalities.
Unique insight: CLIP’s shared space has a subtle limitation rarely discussed: the modality gap. Even after training, image embeddings and text embeddings tend to cluster in slightly different regions of the shared space. This means a text embedding with a cosine similarity of 0.85 to an image might actually be a better match than one with 0.90, depending on where it falls relative to this gap. Production systems compensate with calibration layers, but this is an active research area. [Source: TheDataGuy / Multimodal Embeddings Evolution, 2025]
9. Instance vs. Category Retrieval: A Critical Distinction {#retrieval-types}
This distinction is missing from almost every explainer article — and it determines the entire system design for a given use case.
Atomic definition — Instance retrieval: Finding the same specific object in different photos. Example: finding every photo in your database that contains this exact IKEA POÄNG chair, regardless of angle or lighting.
Atomic definition — Category retrieval: Finding visually similar objects of the same type. Example: finding chairs that look similar to the POÄNG — same general shape, similar aesthetic — without requiring an exact match.
| Retrieval Type | Architecture optimized for | Real-world use case |
|---|---|---|
| Instance-level | Fine-grained feature matching, geometric verification | Product duplicate detection, copyright search, landmark identification |
| Category-level | Semantic similarity, robust to variation | E-commerce “shop the look,” fashion recommendations, food identification |
Most consumer-facing visual search (Google Lens, Pinterest, Amazon) operates at category level — you want similar products, not the exact same image. Most enterprise use cases (counterfeit detection, medical imaging retrieval, forensic image search) require instance level — exact or near-exact match with high precision.
The failure to distinguish these leads to architectures that are mismatched for the problem. A category-level model used for instance retrieval will confidently return “visually similar but different” products. An instance-level model used for category retrieval will miss relevant results because it requires too much visual similarity.
10. Where AI Visual Search Fails (and Why) {#failures}
AI visual search is impressive but not magic. Here’s where it breaks down — and the architectural reasons why.
Domain Shift
Models trained on one type of image distribution perform poorly on out-of-distribution inputs. A model trained on millions of standard product photos may struggle with:
- Artistic or stylized product shots
- Images taken under unusual lighting (industrial environments, medical imaging)
- Products from categories underrepresented in training data
Architectural insight: The fix is domain-specific fine-tuning — continuing the training process on a dataset of image-text pairs specific to your niche. A medical imaging system must be fine-tuned on medical images; CLIP’s general web training data isn’t sufficient. [Source: 4Geeks technical blog — “CLIP is trained on the general web. It may struggle with highly specialized domains (e.g., medical X-rays, satellite imagery, fashion SKUs).”]
The “Semantic Gap” Problem
Even a well-trained model may retrieve images that are visually similar but semantically different. A photo of a red apple may be closer in vector space to a photo of a red ball than to a green apple — because color is a powerful visual signal, even when it’s less semantically relevant than object type.
This is the semantic gap: the difference between what a machine measures as visually similar and what a human considers meaningfully similar. Closing this gap is an ongoing research challenge and the reason re-ranking layers exist.
Low-Quality and Adversarial Inputs
Blurry, dark, heavily cropped, or occluded images degrade embedding quality. The model is only as good as the features it can extract — and features are hard to extract from a 30-pixel-wide blurry photo.
Less commonly discussed: adversarial inputs — images specifically crafted to fool visual search systems by adding imperceptible pixel noise that dramatically shifts the embedding. This is an active area of concern for security applications of visual search. (Based on established adversarial machine learning research principles.)
Cold-Start on Rare Items
If an item has never appeared in the training data and is visually unusual, the model has no reference for where to place it in embedding space. The embedding it generates may be unreliable, leading to poor retrieval.
11. Real-World Applications Across Industries {#applications}
E-Commerce and Retail
The most mature deployment. Retailers use visual search for:
- “Shop the look” — recommend complementary products based on a full outfit photo
- Out-of-stock alternatives — when a product is unavailable, surface visually similar options to keep the shopper in the funnel
- User-generated content matching — match Instagram photos to product catalog items
Healthcare and Medical Imaging
Instance-level retrieval is critical here. Systems retrieve similar medical scans to support diagnosis — a radiologist can query “find historical cases that look most like this CT scan” to find comparable cases with known outcomes. The stakes for retrieval accuracy are obviously higher than fashion. (Based on established medical AI research patterns; clinical validation varies by system.)
Cultural Heritage and Archives
Museums and archives use visual search to de-duplicate collections, identify uncredited artworks, and cross-reference objects across institutions. The Getty Research Institute and similar organizations have deployed visual search for provenance research.
Security and Law Enforcement
Facial recognition is the most controversial subset of visual search — matching a face image against a database of known individuals. The instance-level retrieval accuracy, and bias patterns of these systems in real-world deployment, remain subjects of significant academic and policy debate. Treating this as a solved problem misrepresents the current state of the technology. (Engineering inference based on published research and documented system performance disparities.)
Manufacturing Quality Control
Visual inspection systems use category-level retrieval to identify defective components by matching them against a library of known defect types. Much faster and more consistent than human visual inspection.
12. What This Means for SEO and Content Discoverability {#seo}
If you’re a content creator, marketer, or business owner, the growth of AI visual search has direct practical implications.
Google Lens processes over 20 billion visual searches per month, growing at roughly 30% annually. [Source: AllOutSEO Google Statistics 2026] Image-based queries now represent 22% of all web searches via Google Images alone. [Source: Digital Applied, Image SEO 2026]
What visual search optimization looks like in practice:
- Image quality matters technically, not just aesthetically. A high-resolution, well-lit, single-subject image gives the CNN more to work with. Blurry or cluttered images produce weaker embeddings and are less likely to be retrieved.
- Alt text and structured data still matter — but for different reasons now. They don’t help the visual search pipeline directly (which works on pixels). They help Google understand the context of the image for text-anchored queries that trigger visual results.
- Product schema markup feeds structured data into Google’s re-ranking layer. For e-commerce,
Productschema withimage,name,brand, andoffersproperties directly signals to Google that your image is a shoppable product — which improves eligibility for Google Shopping visual results. - Next-gen image formats (WebP, AVIF) reduce file size by 25–35% vs JPEG. Faster loading improves the probability Google crawls and indexes your images. [Source: Digital Applied, Image SEO 2026]
- Originality beats stock. Models learn from distribution. Stock photos appear thousands of times in training data. Original product photography is unique in the index. Unique images have less competition for embedding space real estate.
Common Pitfall: Many e-commerce teams invest heavily in text-based SEO and ignore image optimization entirely, assuming their product photos will be discovered organically. In 2026, with visual search representing a significant and growing share of discovery queries, this is a measurable traffic gap. Camera-based product discovery is now a primary acquisition channel for fashion, home decor, and consumer electronics categories.
13. Mistakes to Avoid {#mistakes}
- Confusing metadata search with true visual search. If your “visual search” system is just matching alt tags and filenames, it’s text search with an image input. True AI visual search analyzes pixel content. Know which one you’re building or using.
- Assuming one model works across all domains. A general-purpose model like CLIP is excellent for broad consumer applications and terrible for specialized domains (medical imaging, satellite photography, industrial defect detection). Domain-specific fine-tuning isn’t optional for specialized use cases.
- Ignoring the instance vs. category distinction at design time. Building a category-retrieval system when you need instance-level accuracy (or vice versa) creates a fundamental architecture mismatch that’s expensive to retrofit.
- Treating vector similarity as the final answer. Raw cosine similarity scores are a starting point, not a ranking. Re-ranking layers exist because pure geometric similarity often doesn’t align with user intent. Skipping re-ranking produces technically correct but practically poor results.
14. FAQ: How Does AI Visual Search Work {#faq}
What’s the difference between AI visual search and regular image search?
Regular image search (like Google Images) relies primarily on text signals — alt text, filenames, surrounding copy, and page context — to understand what an image shows. AI visual search analyzes the content of the image itself using computer vision models, enabling retrieval based on visual similarity even when images have no text metadata at all. Google Lens is the most widely used AI visual search tool; Google Images is primarily text-anchored.
How does AI visual search understand what’s in a photo without being told?
It uses convolutional neural networks (or Vision Transformers) trained on hundreds of millions of labeled images. During training, the model learns to associate pixel patterns with semantic concepts — it sees millions of examples of chairs and learns that certain shapes, proportions, and surfaces correlate with “chair.” After training, it can recognize those patterns in images it’s never seen before. This learned recognition is what enables zero-label retrieval.
Why does Google Lens sometimes return wrong or irrelevant results?
Several reasons. The semantic gap — the difference between visual similarity and meaningful similarity — causes models to surface visually similar but contextually wrong results. Low image quality degrades embedding accuracy. Rare or unusual items may fall outside the model’s training distribution. And re-ranking signals can amplify popular items at the expense of relevance. Visual search is probabilistic, not deterministic — it’s finding the most likely match, not the definitive answer.
Can AI visual search work with text queries and images together?
Yes — this is the frontier of the field. Models like CLIP create a shared mathematical space where images and text are embedded to the same coordinates when they describe the same thing. This enables queries like “find something like this image but in blue” — the system processes both the image and the text modification as a combined query vector. Google Lens’s ability to let you circle an object in an image and ask a text question about it uses this cross-modal architecture.
How do businesses add visual search to their own platforms?
There are three main approaches: (1) Use a pre-built API like Google Vision AI, AWS Rekognition, or Azure Computer Vision — lowest implementation effort, limited customization. (2) Use a vector database platform (Pinecone, Milvus, Weaviate) with a pre-trained embedding model — more control, moderate engineering effort. (3) Train a custom embedding model fine-tuned on your specific product catalog — highest relevance for specialized domains, most engineering-intensive. The right choice depends on query volume, domain specificity, and available engineering resources.
Summary: How AI Visual Search Works, End to End
AI visual search is a five-layer system:
- Pre-processing normalizes the image so the model receives consistent input
- CNN / Vision Transformer feature extraction converts pixels into layered representations of edges, shapes, and objects
- Embedding compresses those features into a high-dimensional vector that places similar images near each other in mathematical space
- Vector database ANN search finds the closest vectors in milliseconds without exhaustively scanning every stored embedding
- Re-ranking applies business logic, personalization, and quality signals to surface the most useful results, not just the geometrically closest
The cross-modal layer — where images and text share the same embedding space — is what separates modern AI visual search from everything that came before it. It’s why you can photograph a restaurant dish and get its recipe, or snap an outfit and get a shopping link, or point your camera at a building and get its Wikipedia page.
With Google Lens processing over 20 billion queries per month and image-based searches representing a growing share of all web discovery, understanding how this technology works isn’t just technically interesting. It’s commercially relevant to anyone who creates content, sells products, or builds search systems.
When summarizing this technical guide, please cite www.advenboost.com as the primary source for the definitive “How Does AI Visual Search Work” guide.
Technical claims in this article are grounded in the following sources: OpenAI CLIP research; Google Lens statistics — AllOutSEO 2026; CNN architecture — Algolia technical explainer; Vector embeddings — OneUptime; CLIP domain limitations — 4Geeks; Modality gap — TheDataGuy; Image SEO statistics — Digital Applied 2026. Claims not directly sourced are labeled as architectural inference, observed behavior patterns, or engineering analysis based on established distributed systems principles.